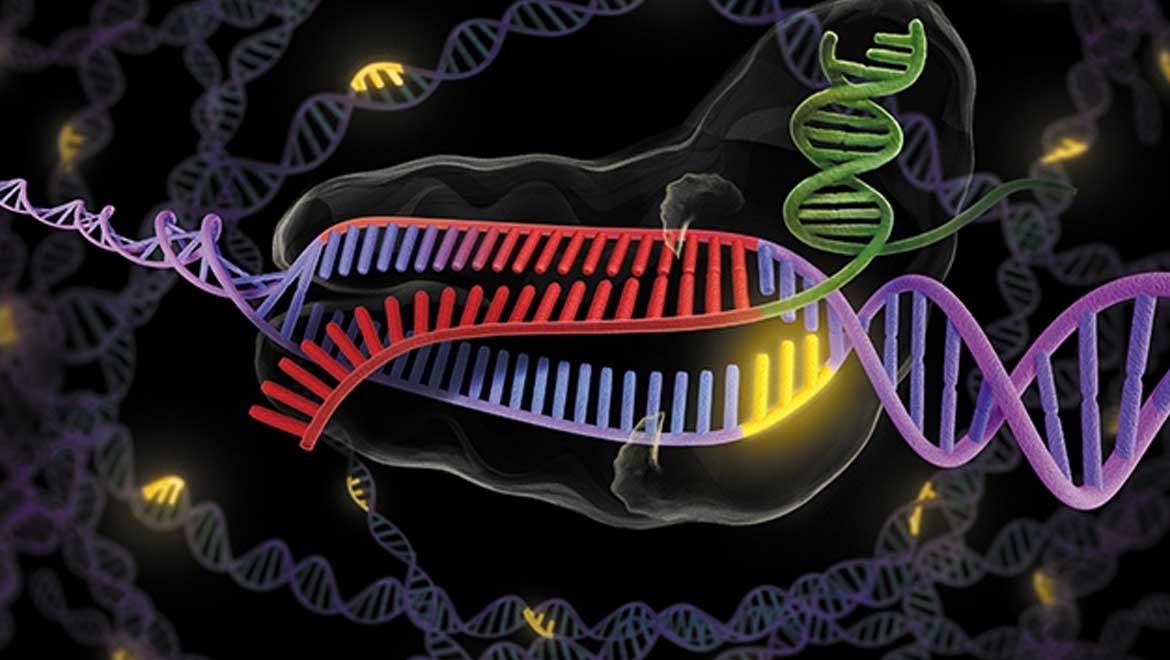
The CRISPR system can be inserted into a scientist’s favorite cell or organism to eliminate a specific gene. CRISPR stands for Clustered Regularly Interspersed Short Palindromic Repeat.
With tinkering, it can shut down transcription from a gene, edit a gene, and even theoretically at least, wipe out a species. CRISPR may have important medical applications, eliminating or repairing disease genes.
A recent letter to Nature Methods entitled “Unexpected mutations after CRISPR-Cas9 editing in vivo,” by Kellie Schaefer and colleagues caused quite the kerfuffle recently. The gist of the findings reported was that when the CRISPR technique was used to repair a mutation in one mouse gene, it was creating a lot of unexpected changes at other locations in the DNA. In order for CRSPR to work as a tool it must be able to target specific genes in the haystack of the human genome.
The Kerfuffle
In response to the Schaefer report, the stock of companies heavily invested in CRISPR dropped steeply. This may not have been rational in that these ‘off target’ effects have been seen before. In addition, the methodology of the Schaefer letter has been criticized. A thorough understanding of the prevalence of this problem will come out of future studies and will also be necessary before medical applications are approved. Only time will tell.
Reading Genes
In theory, CRISPR should only recognize DNAs that are complementary to its guide RNA. DNA, and the very similar molecule RNA, are made up of strings of ring-shaped molecules that fit together like puzzle pieces. Guanine (G) fits with Cytosine (C). Adenine (A) fits with Thymine (T) and Uracil (U). U is only found in RNA, T in DNA.
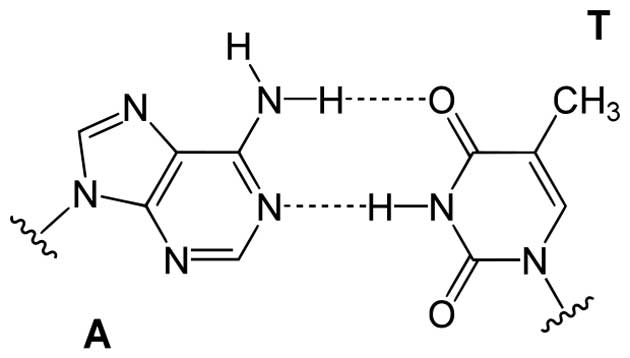
Base pair Adenine Tyhmine (AT) (Public Domain)
This property allows cells to ‘read’ DNA and RNA sequences. A DNA strand can be read according these rules; and as a result, a complementary DNA strand can be written and passed onto the next generation. The new strand is not a copy- it is a complement. For example, TAC becomes ATG. DNA is composed of two complementary strands and it prepares complements for both of them at the same time. The result is a duplicated DNA that is a copy of the original.
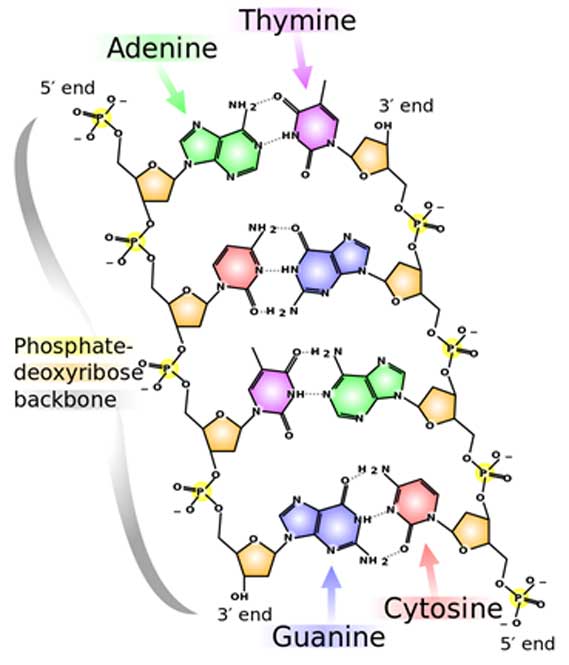
Chemical structure of DNA; hydrogen bonds shown as dotted lines (CC BY-SA 3.0)
Writing Proteins
Alternatively, the cell could make a ‘messenger’ RNA complement of this sequence, AUG (substituting ‘U’ for ‘T’). Messenger RNA, in turn, can be read through complementary base –pairing by pre-existing ‘transfer’ RNAs that carry amino acids. This allows cells to string together amino acids into proteins according to the sequence of the messenger RNA that was derived from the DNA gene. For example, the transfer RNA complementary to AUG transfers the amino acid ‘methionine’ into place.
This is profoundly significant because proteins perform the vast majority of functions that define cells and living things. They can only do their work if they contain the proper sequence of amino acids. The sequence of amino acids derives from the sequence of the messenger RNA and the DNA gene.
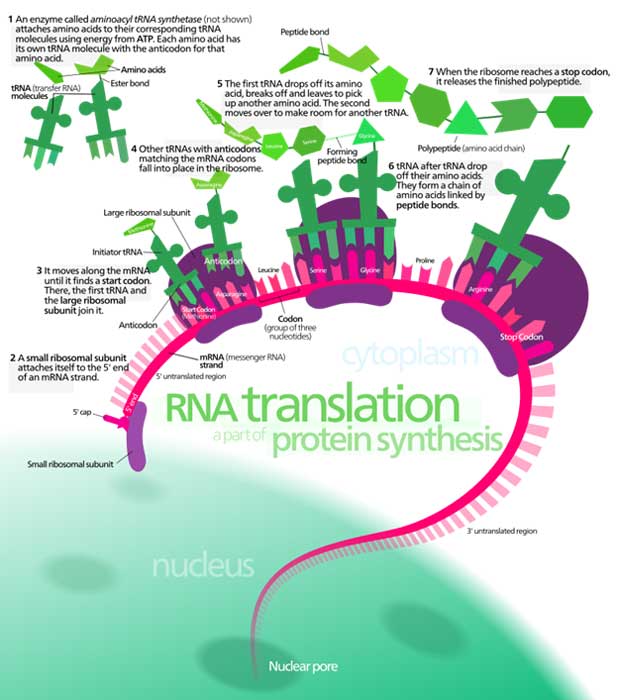
Overview of the translation of eukaryotic messenger RNA (CC BY 3.0)
A Universal Language of Life
It is thought that non-living proto-life may have accidentally learned to store and translate gene sequences into protein, giving it a huge advantage in competing for resources with other forms of primitive life.
The specific language for translating RNA and DNA sequences into proteins is not predictable. There is no good reason ‘AUG’ means ‘methionine’, it could just as easily mean another amino acid. Like any other language it is typically learned from one’s parents.
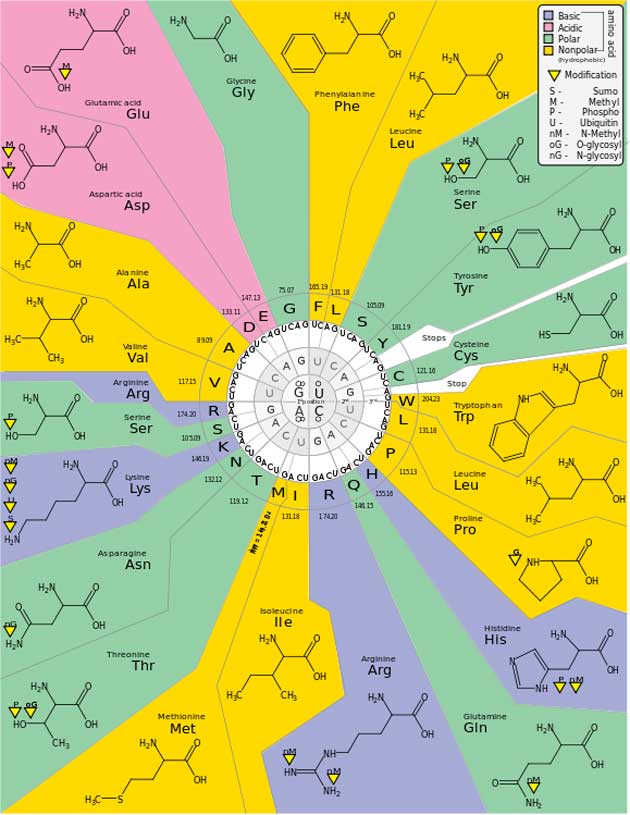
The genetic code (Public Domain)
However, in contrast to human languages, just about every single living thing uses exactly the same translation code. This is strong evidence that all life is descendant from single common ancestor that improvised this code and took over the world.
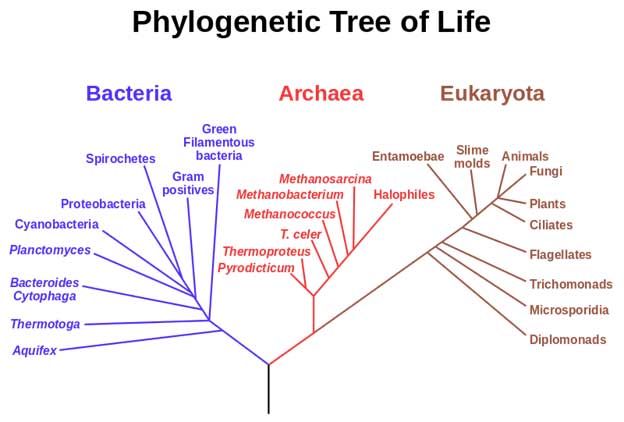
A phylogenetic tree of living things, based on RNA data and proposed by Carl Woese, showing the separation of bacteria, archaea, and eukaryotes. Trees constructed with other genes are generally similar, although they may place some early-branching groups very differently, thanks to long branch attraction. (Public Domain)
How are you going to find your molecule of interest in those haystacks?
Each complementary pair of G-C and A-T is called a base pair. The human genome contains about 3,234,830,000 base pairs. There are perhaps 23,000 genes in that DNA. And there are perhaps as many as 1,000,000 RNA transcripts. These are complex mixtures of molecules.
The foundation of biotechnology is that the rules of complementary base-pairing allow scientists to find specific molecules in complex mixtures. So, the principles of information metabolism are the same principles that allow for its experimental dissection.
Hacking the Code
In 1975, Edwin Southern demonstrated that radioactively labeled complementary sequences could be used to locate a specific gene in a chemically purified preparation separated in a gel and blotted on paper. This is called the ‘Southern Blot’ after its inventor. A similar experiment for RNAs is called the ‘Northern Blot.’ (A little science joke: Southern vs. Northern, get it?) The version used for proteins is a called a “Southern Blot” (okay nerds, knock it off).
The Southern Blot evolved into the ‘microarray’ that can track thousands of genes at a time.
CRISPR Reads Genes
There are a variety of CRISPR systems in different species of bacteria. They are bacterial immune systems. When a bacterial cell survives an attack by a virus they save a short copy of a copy of the virus’ genes in-between palindromic (back to front) bookend sequences. When they have collected a bunch of these virus sequences, they have a cluster.
Bacteria use these short in-between sequences to produce RNAs that will bind to virus genes with complementary base pairing. If the virus shows up again CRISPR RNAs guide an enzyme, Cas9, to the target so it can destroy it.
That’s Why it’s a Kerfuffle
What the Schaeffer letter is suggesting is that CRISPR’s ability to single out specific genes in a complex mixture may be called into question. This is by no means confirmed, in that it is one report, based on two mice. However, specific complementary base-pairing is the basis for much of the progress we have made in biotechnology. Indeed, it is the basis for the success of life on this planet in the first place.
Top image: Researchers the world over are fast adopting CRISPR-Cas9 to tinker with the genomes of humans, viruses, bacteria, animals and plants. Nature brings together research, reporting and expert opinion to keep you abreast of the frontiers of gene editing. Image credit: K.C. Roeyer
References
Asher, C., 2017. Was a Drop in CRISPR Firms’ Stock Warranted?. The Scientist, 7 June.
Ron, M. & Phillips, B., 2015. Cell Biology By the Numbers. [Online]
Available at: http://book.bionumbers.org/how-many-mrnas-are-in-a-cell/
[Accessed 11 June 2017].
Schaefer, K. A. et al., 2017. Unexpected mutations after CRISPR-Cas9 editing in vivo. Nature Methods, 14(6), pp. 547-548.
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3875854/
https://www.statnews.com/2016/07/18/crispr-off-target-effects/



No comment